
관심쟁이 영호
[#2 이미지 검색 프로젝트] 크롤링 2탄 ㅣ Json 형태로 Request하기 ㅣ Ajax 동적으로 API 요청하기 본문
[#2 이미지 검색 프로젝트] 크롤링 2탄 ㅣ Json 형태로 Request하기 ㅣ Ajax 동적으로 API 요청하기
관심쟁이 영호 2021. 9. 16. 01:39이전에 포스팅한
[#1 SSP] 크롤링을 해보자!
SSP에서 가장 핵심적인 크롤링을 해보자. 목차 툴 라이브러리 설치 User-Agent 쿠팡에서 정보 긁어오기 네이버에서 정보 긁어오기 번개장터에서 정보 긁어오기 툴 language : python 3.9.7 ide : Visual Studio
bestkingit.tistory.com
포스팅을 계속해서 코딩하다 보니까 치명적인 오류를 발견하였다.
목차
- 문제
- 해결방법
- Ajax 요청 보내기
- 또 다른 문제
- 문제 해결
- 리팩토링
문제와 해결
네이버 홈페이지를 들어가 보았다. 처음에 페이지가 로드되었을 때는 5개 정도의 상품이 로드되었다.
그리고 스크롤이 어느 정도 내려가야 Ajax-Json 통신으로 데이터를 새롭게 받는 것을 볼 수 있다.
이전 코드로 작성된 크롤링을 실행하면, 올바르게 작성되었지만 상품이 5개까지 밖에 없다..
그래서 수정하기로 했다!
-Json 통신을 수행하는 URL을 찾아라!!
"검색" 버튼을 클릭했을 때, 날아가는 URL을 찾아야 한다.
실제 사이트에서 network탭에서 찾아보자.
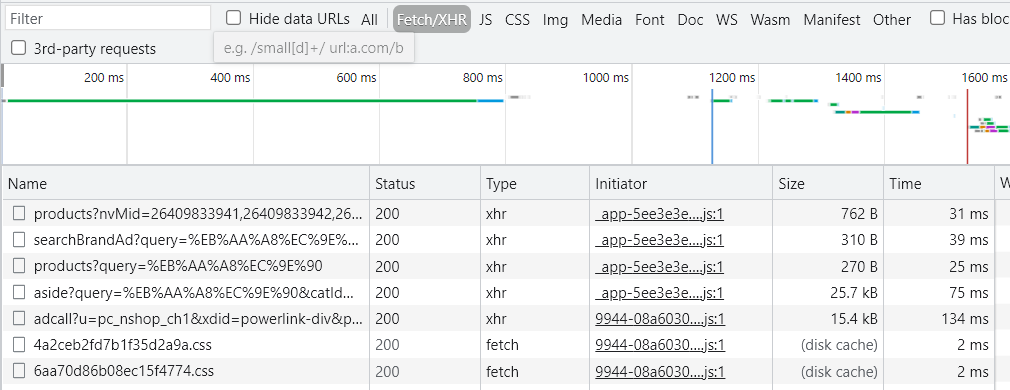
저기서 어떤 것인지 감이 안 온다.. 처음엔 막막했다.
하나씩 눌러가며 뒤져보아도, 데이터가 넘어오는 것을 알아볼 수가 없었다.
그래서 header에 Request URL을 전부 복붙 하여 URL GET 요청을 하나하나 해보기 시작했다.
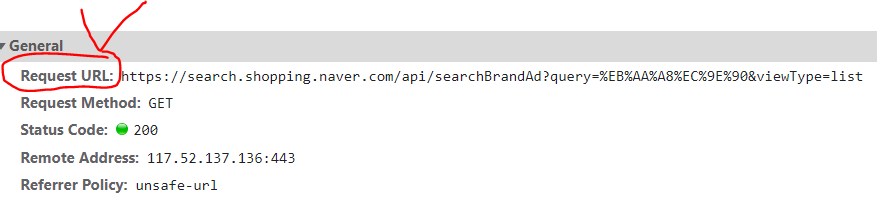
어랍쇼? 이게 되네? 이걸 나진이(-틀-)?

오오오오오옹오오오오오오 JSON 넘어온다!!!!!
이 글을 보는 누군가도 "네이버 쇼핑"에서 답답한 심정을 느꼈을 것이다.
십 년 묵은 체증이 내려가길 바란다.
그러면 이거 바로 받아야지?
근데 그전에... 나는 스크롤을 통해서 요청을 했지만 크롤링 프로그램에선 어떻게 요청을 보내야 하나?
페이지 URL을 보내면 또 5개가 나올 텐데?
그래서 찾아본 곳이 다음 블로그 글이다! 도움이 많이 되었다.
selenium사용하지 않고 네이버쇼핑 검색결과 크롤링하기
네이버 쇼핑의 검색 결과가 필요해졌습니다. 검색 페이지 크롤링하면 되니까 어렵지 않게 할 수 있을 거라고 생각했었는데 그게 아니었습니다. 대신 검색정보를 담고 있는 JSON파일을 찾을 수 있
kwonkyo.tistory.com
Ajax 요청 보내기
Ajax를 Get Method로 보냈을 건데.. 내가 어떻게 만드냐..?
네이버 회사에서 나온 것일 텐데
그래서 좋은 방법을 알았지~~
- cURL (bash)로 복사해주자!

※ cURL 이란? : cURL은 다양한 프로토콜 요청을 지원해주는 것이라고 생각하자!
저기에서 내가 복사한 것은, 내가 보낸 요청을 cURL (bash)로 다운로드가 되는 것이다.
- 저러한 cURL을 파이썬 코드로 변환해주는 사이트로 가자!
Convert curl command syntax to Python requests, Ansible URI, browser fetch, MATLAB, Node.js, R, PHP, Strest, Go, Dart, Java, JSO
Language Ansible Browser (fetch) Dart Elixir Go Java JSON Node.js (fetch) Node.js (request) MATLAB PHP Python R Rust Strest
curl.trillworks.com
여기서 Python 코드로 변환하여 복붙 하면 Json 호출 끝
호출받은 것에서 내가 필요한 데이터를 추출하여 뽑아보자!
import requests #requests 라이브러리 import
import json
# http header 설정
headers = {
'authority': 'search.shopping.naver.com',
'sec-ch-ua': '"Google Chrome";v="93", " Not;A Brand";v="99", "Chromium";v="93"',
'accept': 'application/json, text/plain, */*',
'sec-ch-ua-mobile': '?0',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'cors',
'sec-fetch-dest': 'empty',
'referer': 'https://search.shopping.naver.com/search/all?query=%EB%AA%A8%EC%9E%90&frm=NVSHATC&prevQuery=%EB%83%89%EC%9E%A5%EA%B3%A0',
'accept-language': 'ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7',
'cookie': 'NNB=NOLCMFH6MS3WA; NDARK=Y; _ga=GA1.2.36707839.1627031989; _ga_7VKFYR6RV1=GS1.1.1627031988.1.1.1627032122.60; nx_ssl=2; AD_SHP_BID=23; spage_uid=; sus_val=VXtY32Une32saj6a3yBFPHvC',
}
# parameter 설정
params = (
('query', '\uBAA8\uC790'),
('catId', '50000181'),
)
# 받은 Json 저장
response = requests.get('https://search.shopping.naver.com/api/search/aside', headers=headers, params=params)
# json을 리스트로 받기
itemlist = json.loads(response.text)
# 추출하려는 값의 key를 입력
for i in itemlist['luckyToday']['items']:
title = i['productName']
price = i['price']
print('productName=',title,'price=',price)굳!

완료!
또 다른 문제
받아오는 데이터의 크기를 보니까 13개의 상품을 받아온다..
그럼... 2페이지는..? 3페이지는? 노답이다..
그래서 request 요청에 대해서 조금 만져보았다.
다음 사진을 보자.
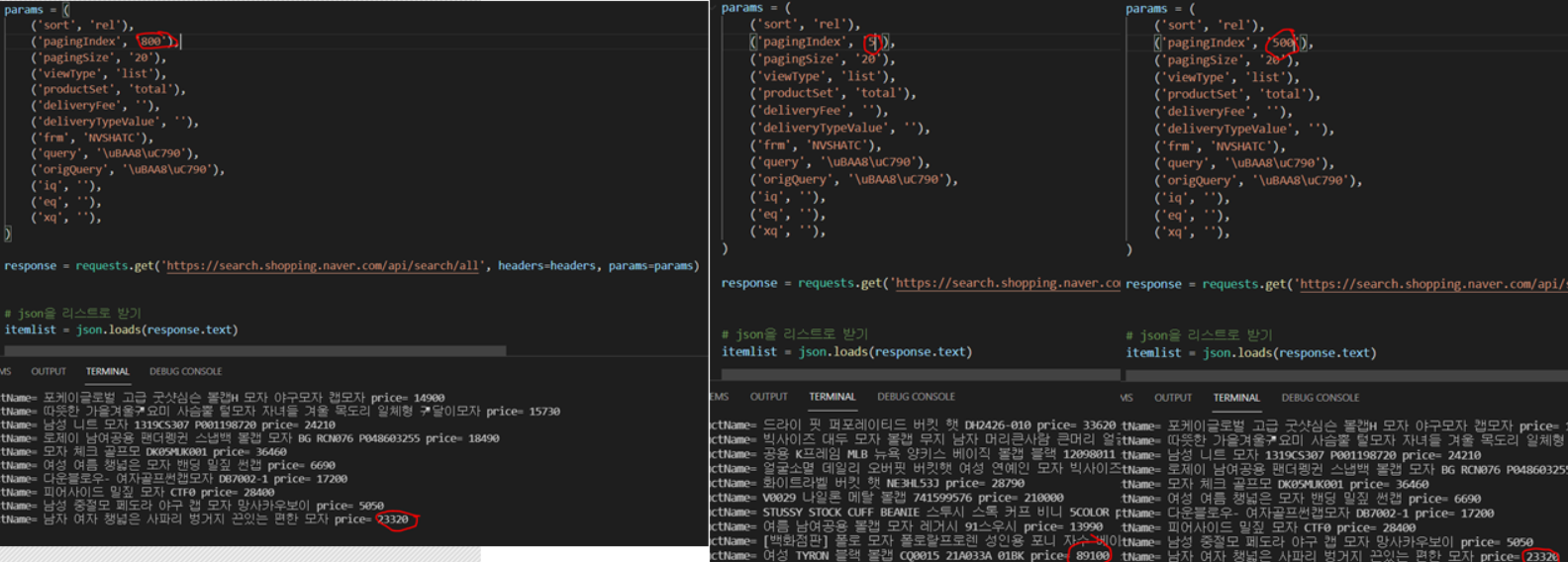
잘 보일지는 모르겠다..
params 설정 부분에 "pagingIndex"의 value를 바꾸어주었다.
계속해서 데이터가 바뀌는 것을 볼 수 있었다. (페이지 개념이겠지!)
1000, 800 등과 같은 아주 큰 수로 설정했을 때, 1000과 800에서의 데이터는 똑같다.
너무나 큰 수를 입력하게 되면, 가장 마지막의 데이터를 Response 한다.
- 전략
크롤링할 때, "pagingIndex"의 value를 기준으로 여러 번 한다.
previous data를 가지고 새롭게 받은 데이터가 previous data와 같다면 크롤링을 종료한다.
(더 이상 반환받을 데이터가 없기 때문에!)
- previous data를 가져야 하는 이유
어떤 데이터를 입력받아 크롤링을 실행할지, 모른다.
사용자가 말도 안 되는 검색어를 입력한다면? 결과 페이지가 2개로 작을 수도 있다. 없을 수도 있다. 그래서 요청을 하고 이전에 응답을 받은 값을 저장해두었다가 다음 요청에 대한 응답이랑 비교를 해준다. 같은 값이 나오면 while문을 종료한다.
- 너무나 많은 메모리를 소모하지 않을까?
previous 변수에 계속해서 새로운 값을 할당해서 변수로 인한 고정적인 메모리 사용은 계속해서 유지가 된다.
(그리고 크롤링 서버는 크롤링과 DB Write만 하기 때문에 비교적 메모리 여유가 있을 것이다!)
but, 많은 요청이 들어온다면 (고정적 메모리 사용) x 데이터가 없는 요청 수.. 거의 무한으로 증가할 수 있다.
지금은 많은 고민을 하지 않고, 개발을 하자.
추 후에, 홀수의 응답 값 내용만 비교 또는 마지막 5개의 응답 값 내용만 비교 등등으로 고치면 된다!
문제 해결하기
먼저 1~9의 pagingIndex를 요청하도록 코드를 작성하였다.
import requests #requests 라이브러리 import
import json
#헤더는 고정이다.
headers = {
'authority': 'search.shopping.naver.com',
'sec-ch-ua': '"Google Chrome";v="93", " Not;A Brand";v="99", "Chromium";v="93"',
'accept': 'application/json, text/plain, */*',
'sec-ch-ua-mobile': '?0',
'logic': 'PART',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'cors',
'sec-fetch-dest': 'empty',
'referer': 'https://search.shopping.naver.com/search/all?query=%EB%AA%A8%EC%9E%90&frm=NVSHATC&prevQuery=%EB%AA%A8%EC%9E%90',
'accept-language': 'ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7',
'cookie': 'NNB=NOLCMFH6MS3WA; NDARK=Y; _ga=GA1.2.36707839.1627031989; _ga_7VKFYR6RV1=GS1.1.1627031988.1.1.1627032122.60; nx_ssl=2; AD_SHP_BID=23; spage_uid=; BMR=s=1631641124319&r=https%3A%2F%2Fm.blog.naver.com%2FPostView.naver%3FisHttpsRedirect%3Dtrue%26blogId%3Dteenager4282%26logNo%3D220962394004&r2=https%3A%2F%2Fwww.google.com%2F; sus_val=G6C9UIqZv3AcfjeJP38FmfXG',
}
responseList = [] # previous랑 비교하기 위한 로직이다.
number = 1
while number < 10 :
print('number = ',number)
pageingIndex = number
params = (
('sort', 'rel'),
('pagingIndex', 9),
('pagingSize', '20'),
('viewType', 'list'),
('productSet', 'total'),
('deliveryFee', ''),
('deliveryTypeValue', ''),
('frm', 'NVSHATC'),
('query', '\uBAA8\uC790'),
('origQuery', '\uBAA8\uC790'),
('iq', ''),
('eq', ''),
('xq', ''),
)
response = requests.get('https://search.shopping.naver.com/api/search/all', headers=headers, params=params)
# json을 리스트로 받기
itemlist = json.loads(response.text)
# 추출하려는 값의 key를 입력
for i in itemlist['shoppingResult']['products']:
title = i['productName']
price = i['price']
print('productName=',title,'price=',price)
number = number + 1
python이 익숙하지 않다 보니.. 코드가 개판 같기도 하고..
콘솔을 살펴보자!

2, 3, 4 마다 달라지는 모습을 볼 수가 있다.
ㅇㅋ 일단 number 값에 따라 다른 request 완료.
그럼 이제 받은 response를 이전에 받은 response와 같은지 비교해보자!
단, 첫 번째 비교에는 list가 null 값이니 number가 1일 때는 로직이 수행되지 않도록 한다.
import requests #requests 라이브러리 import
import json
headers = {
'authority': 'search.shopping.naver.com',
'sec-ch-ua': '"Google Chrome";v="93", " Not;A Brand";v="99", "Chromium";v="93"',
'accept': 'application/json, text/plain, */*',
'sec-ch-ua-mobile': '?0',
'logic': 'PART',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'cors',
'sec-fetch-dest': 'empty',
'referer': 'https://search.shopping.naver.com/search/all?query=%EB%AA%A8%EC%9E%90&frm=NVSHATC&prevQuery=%EB%AA%A8%EC%9E%90',
'accept-language': 'ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7',
'cookie': 'NNB=NOLCMFH6MS3WA; NDARK=Y; _ga=GA1.2.36707839.1627031989; _ga_7VKFYR6RV1=GS1.1.1627031988.1.1.1627032122.60; nx_ssl=2; AD_SHP_BID=23; spage_uid=; BMR=s=1631641124319&r=https%3A%2F%2Fm.blog.naver.com%2FPostView.naver%3FisHttpsRedirect%3Dtrue%26blogId%3Dteenager4282%26logNo%3D220962394004&r2=https%3A%2F%2Fwww.google.com%2F; sus_val=G6C9UIqZv3AcfjeJP38FmfXG',
}
previousItemList = []
preResponse = ''
number = 1
while number < 100 :
print('number = ',number)
pageingIndex = number
params = (
('sort', 'rel'),
('pagingIndex', pageingIndex),
('pagingSize', '20'),
('viewType', 'list'),
('productSet', 'total'),
('deliveryFee', ''),
('deliveryTypeValue', ''),
('frm', 'NVSHATC'),
('query', '\uBAA8\uC790'),
('origQuery', '\uBAA8\uC790'),
('iq', ''),
('eq', ''),
('xq', ''),
)
response = requests.get('https://search.shopping.naver.com/api/search/all', headers=headers, params=params)
# json을 리스트로 받기
itemlist = json.loads(response.text)
# 첫번째 호출에는 list가 비교가 안되니 continue를 한다.
if number == 1 :
number = number + 1
previousItemList = itemlist
continue
#아래 if문 비교를 수정해야할 듯 하다..
if previousItemList['shoppingResult']['products'][0]['productName'] == itemlist['shoppingResult']['products'][0]['productName']:
print('같아서 끝-----')
break
previousItemList = itemlist
# 추출하려는 값의 key를 입력
for i in itemlist['shoppingResult']['products']:
title = i['productName']
price = i['price']
print('productName=',title,'price=',price)
number = number + 1로직은 완성되었다.
똑같은 응답이 왔을 때(더 이상 받을 값이 없을 때), 반복문을 종료하도록 만들자.
예시로 number를 10000부터 받도록 해보았다.
위의 코드에서 number = 1을 10000으로 바꾸자.
그리고 continue가 포함되어있는 if 체크를 10000으로 바꾸어주자.
number = 10000# 10번만 돌리자!
while number < 10011 : if number == 10000 :
number = number + 1
previousItemList = itemlist
continue결과는
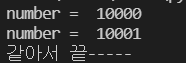
첫 번째 호출 때는 같은 응답을 받았는지 체크를 할 필요가 없어서 넘어갔다.
두 번째 호출 때는 10000의 호출과 똑같은 값이어서
while문을 종료한 모습이다.
코드가 너무 어지럽다..
이제 리펙토링을 해보자.
리팩토링
import requests #requests 라이브러리 import
import json
# Request에서 사용될 header 생성
headers = {
'authority': 'search.shopping.naver.com',
'sec-ch-ua': '"Google Chrome";v="93", " Not;A Brand";v="99", "Chromium";v="93"',
'accept': 'application/json, text/plain, */*',
'sec-ch-ua-mobile': '?0',
'logic': 'PART',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'cors',
'sec-fetch-dest': 'empty',
'referer': 'https://search.shopping.naver.com/search/all?query=%EB%AA%A8%EC%9E%90&frm=NVSHATC&prevQuery=%EB%AA%A8%EC%9E%90',
'accept-language': 'ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7',
'cookie': 'NNB=NOLCMFH6MS3WA; NDARK=Y; _ga=GA1.2.36707839.1627031989; _ga_7VKFYR6RV1=GS1.1.1627031988.1.1.1627032122.60; nx_ssl=2; AD_SHP_BID=23; spage_uid=; BMR=s=1631641124319&r=https%3A%2F%2Fm.blog.naver.com%2FPostView.naver%3FisHttpsRedirect%3Dtrue%26blogId%3Dteenager4282%26logNo%3D220962394004&r2=https%3A%2F%2Fwww.google.com%2F; sus_val=G6C9UIqZv3AcfjeJP38FmfXG',
}
## 함수 부분 ##
#####################################################################################################################
def isRepeat(previousItemList, itemList) :
#같은 값을 응답받으면 True 리턴
if previousItemList['shoppingResult']['products'][0]['productName'] == itemList['shoppingResult']['products'][0]['productName']:
print('같아서 끝-----')
return True
#아니면 False 리턴
return False
def printData(itemList) :
# 추출하려는 값의 key를 입력
for i in itemList['shoppingResult']['products']:
title = i['productName']
price = i['price']
print('productName=',title,'price=',price)
def makeRequestAndGetResponse(number) :
pageingIndex = number
params = (
('sort', 'rel'),
('pagingIndex', pageingIndex),
('pagingSize', '20'),
('viewType', 'list'),
('productSet', 'total'),
('deliveryFee', ''),
('deliveryTypeValue', ''),
('frm', 'NVSHATC'),
('query', '\uBAA8\uC790'),
('origQuery', '\uBAA8\uC790'),
('iq', ''),
('eq', ''),
('xq', ''),
)
response = requests.get('https://search.shopping.naver.com/api/search/all', headers=headers, params=params)
return response
## 로직부분 ##
#####################################################################################################################
# 중복 체크를 위한 변수
previousItemList = []
number = 1
while number < 100 :
print('number = ',number)
# 네이버를 향한 Request 생성 and 네이버로부터 response 받기
response = makeRequestAndGetResponse(number)
# json을 리스트로 받기
itemList = json.loads(response.text)
# 첫번째 호출에는 list가 비교가 안되니 continue를 한다.
if number == 1 :
number = number + 1
previousItemList = itemList
printData(itemList)
continue
# 반복 응답 Check Method
# 응답이 같은 값으로 반복되었는지 확인하는 메서드를 실행한다. True일 경우 중복이라서 break
if isRepeat(previousItemList, itemList) :
break
previousItemList = itemList
printData(itemList)
number = number + 1
훨씬 깔끔하쥬?
다음에는 mySQL에 저장하는 작업을 해보자.
'Project > SSP - 이미지 검색 및 최저가 검색' 카테고리의 다른 글
| [#5 이미지 검색 프로젝트] python http 서버 만들기 (0) | 2021.09.19 |
|---|---|
| [#4 이미지 검색 프로젝트] Python - MySQL 연동하기! (0) | 2021.09.19 |
| [#1 이미지 검색 프로젝트] 크롤링을 해보자! (0) | 2021.09.14 |
| [#0 이미지 검색 프로젝트] 프로젝트 계획 (0) | 2021.09.14 |


