
관심쟁이 영호
[#1 이미지 검색 프로젝트] 크롤링을 해보자! 본문
SSP에서 가장 핵심적인 크롤링을 해보자.
목차
- 툴
- 라이브러리 설치
- User-Agent
- 쿠팡에서 정보 긁어오기
- 네이버에서 정보 긁어오기
- 번개장터에서 정보 긁어오기
툴
- language : python 3.9.7
- ide : Visual Studio Code
- Browser : Google Chrome
라이브러리 설치
- VS Code에서 개발할 폴더를 생성한다.
- 터미널을 켠다.
- 개발 폴더로 디렉터리가 설정되어 있지 않아 있다면, cd 명령어를 통해서 현재 프로젝트 폴더로 이동해주자.
Requests 라이브러리 설치
다음 명령어를 입력하자.
pip install requestsRequests 라이브러리는 html을 받아오는데 도움을 주는 라이브러리이다.
beautifulsoup4 라이브러리 설치
다음 명령어를 입력하자.
pip install beautifulsoup4beautifulsoup4 라이브러리를 통해서 Requests 라이브러리가 받아온 html의 내용을 추출할 것이다.
lxml 라이브러리 설치
pip install lxmlxml 코드 사용을 도와주는 라이브러리이다.
(html이 대표적인 xml코드)
User-Agent
User-Agent는 어떠한 정보를 서버에 요청했을 때, 어느 경로를 통해서 해당 요청을 했는지 알려주는 식별자라고 생각하면 된다.
서버 입장에서는 요청한 주체가 휴대폰 or 웹 브라우저 or 기타 중에서 무엇인지 모른다. 그래서 User-Agent를 통해서 식별하도록 약속하였다.
평소에 사용하고 있는 Chrome, Explorer, iphone, galaxy에서 자동으로 해당 User-Agent를 삽입해준다.
그래서 우리는 모른다!
User-Agent가 필요한 이유는 휴대폰에 보여주는 화면과 컴퓨터로 보여주는 화면이 다르기 때문이다. 또한 Chrome과 Explorer가 또 다르다.
그래서 필요하다!
예시
Mozilla/5.0 (iPad; U; CPU OS 3_2_1 like Mac OS X; en-us) AppleWebKit/531.21.10 (KHTML, like Gecko) Mobile/7B405
위의 예시를 보면
- 브라우저 종류
- 기기 종류
- 기기 cpu 종류
- 기기 os 종류
등등 많은 정보를 가지고 있다.
User-Agent를 확인해보자. 다음 링크를 들어가 보자!
What is my user agent?
Every request your web browser makes includes your User Agent; find out what your browser is sending and what this identifies your system as.
www.whatismybrowser.com
링크에 들어가면 다음 사진과 같은 글이 보일 것이다.

나는 window, chrome을 이용하여 접속했다!
쿠팡에서 정보 긁어오기
코드에 대해서 설명 없이 바로 시작하는 감이 있지만, 코드를 보면 바로 이해가 갈 것이다.
가장 먼저, 쿠팡 사이트 URL이 필요하다.
쿠팡을 접속하여 링크를 가지고 오자!
1. 쿠팡에 접속한다.
2. 검색창에 아무거나 검색해본다.

3. URL을 확인한다.

4. 다른 것을 검색해보자.
나는 "니트"를 검색했다.
5. URL을 확인해보자.

6. 어떤 점이 달라지는지 확인해보자.
URL을 통해서 GET 방식으로 요청하는 것이다.
파라미터는 component, q, channel이 있다. component와 channel은 모르겠고, q에 검색하려는 내용을 넣을 수 있다는 것을 알 수 있다.
7. 찾으려는 내용이 어떻게 구성되어있는지 살펴보자.
내가 찾으려는 내용은 다음 사진에 나와있는 가격과 제목이다.
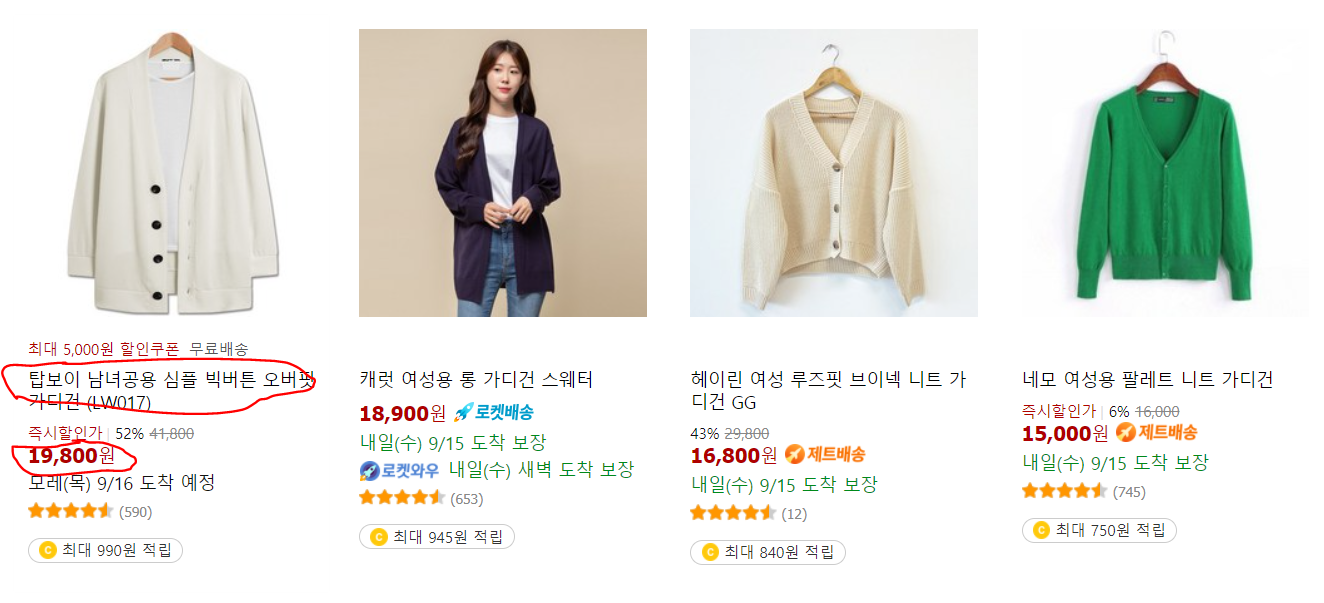
개발자 도구를 실행하여 해당 태그에 대한 정보를 보자.
제목은

"div 태그"와 "class = name" 이라는 것을 알 수 있다.
가격은

"strong 태그" 와 "class = price-value"이다.
그럼 코딩을 해보자!
import requests #requests 라이브러리 import
from bs4 import BeautifulSoup # BeautifulSoup 라이브러리 import
# User-Agent 지정
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'}
# 긁어오려는 사이트 URL
url = "https://www.coupang.com/np/search?component=&q=가디건&channel=user"
# res에는 해당 url의 html이 들어있다.
res = requests.get(url, headers= headers)
# 받아온 html을 soup에 입력
soup = BeautifulSoup(res.text, "lxml")
# 추출한 후 print
print(soup.find("div", attrs ={"class":"name"}).get_text())
print(soup.find("strong", attrs ={"class":"price-value"}).get_text())
URL : 내용을 보면 "가디건"을 통해서 입력했다는 것을 알 수 있다. 사용자가 입력한 값에 따라 해당 "가디건" 부분을 수정해주면 된다.
soup.find : 태그를 찾는 메서드이다. 속성을 추가로 기입하여 더 상세히 찾을 수 있다.
출력 화면은..

정상적으로 출력된 것을 볼 수 있다.
가장 먼저 해당 값이 나왔다고 해당 게시물이 최상단에 있는 것은 아니다.
이유는 html 구조를 css를 통해서 조작했을 가능성이 높기 때문이다!
이제 이러한 내용을 긁어왔을 때, 이미지 객체 추출 작업, DB insert 작업을 해주면 그만이다.
네이버에서 정보 긁어오기
위의 쿠팡과 같은 방법으로 수행한다.
수행한 사이트는 "네이버 쇼핑"이다.
import requests #requests 라이브러리 import
from bs4 import BeautifulSoup # BeautifulSoup 라이브러리 import
# User-Agent 지정
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'}
# 긁어오려는 사이트 URL
url = "https://search.shopping.naver.com/search/all?query=신발&cat_id=&frm=NVSHATC"
# res에는 해당 url의 html이 들어있다.
res = requests.get(url, headers= headers)
# 받아온 html을 soup에 입력
soup = BeautifulSoup(res.text, "lxml")
# 추출한 후 print
print(soup.find("a", attrs ={"class":"basicList_link__1MaTN"}).get_text())
print(soup.find("span", attrs = {"class":"price_num__2WUXn"}).get_text())크롤링해서 정상적으로 받아와 지는 것을 볼 수 있다.
다음으로는 받아온 데이터를 입맛에 맞게 변형해주고 해당 데이터들을 mySQL에 저장해보자.
'Project > SSP - 이미지 검색 및 최저가 검색' 카테고리의 다른 글
| [#5 이미지 검색 프로젝트] python http 서버 만들기 (0) | 2021.09.19 |
|---|---|
| [#4 이미지 검색 프로젝트] Python - MySQL 연동하기! (0) | 2021.09.19 |
| [#2 이미지 검색 프로젝트] 크롤링 2탄 ㅣ Json 형태로 Request하기 ㅣ Ajax 동적으로 API 요청하기 (1) | 2021.09.16 |
| [#0 이미지 검색 프로젝트] 프로젝트 계획 (0) | 2021.09.14 |


